AI and globalization: A WEGG webinar

I was happy to be re-join Women Entrepreneurs Grow Global for a discussion about AI and content globalization and how we’re in the “calm before the storm.” Watch here
Adventures in web globalization, since 2002
I was happy to be re-join Women Entrepreneurs Grow Global for a discussion about AI and content globalization and how we’re in the “calm before the storm.” Watch here
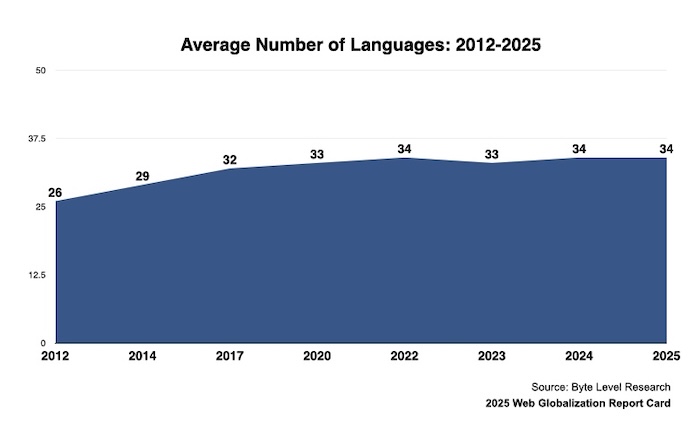
While reviewing websites for the 2025 Web Globalization Report Card I was struck by two things: Combined, I believe we are in the midst of the calm before the storm. …
What’s the world’s most multilingual website? It’s not Facebook. Not Google. Not even Wikipedia. It’s the website of the Jehovah’s Witnesses, at just over 1,000 languages. But Google has been …
There is no internationally accepted definition of what a “translation” icon should look like. But here’s the icon websites tend to use: You see it many places these days — …

The fact that neural machine translation has the word “machine” in it should tell you that this technology has been evolving for a very long time, to back when computers …
Apple may have been late to the machine translation game but they’re working to make up for lost time. They announced today that the Apple Translate app is coming to …

After posting my Web Globalization Report Card video I was asked to comment on the global evolution of a few websites. So I thought I’d put together a brief presentation …

I’m pleased to announce the publication of the 2021 Web Globalization Report Card. This is the 17th annual edition of the Report Card, and it reflects a challenging year. Yet there …

LILT, a Global by Design sponsor, is asking for those of us in the localization industry to give our thoughts on localization trends, best practices and our priorities for the …

LILT, a Global by Design sponsor, is asking for those of us in the localization industry to give our thoughts on localization trends, best practices and our priorities for the …
I recently participated in the TAUS event Reinventing the Translation Industry. The focus of the event was on imagining the translation industry a year from now, in light of our global …
Very cool (and overdue) announcement this morning from the Apple WWDC. The Apple Translate is on its way and is all about voice (and privacy). Here are the supported languages. …
I’m happy to be participating in the upcoming TAUS event: Reinventing the Translation Industry. This virtual event, taking place June 8-18th, poses the question: What will be the state of …
Google announced the addition of five languages today: Kinyarwanda Odia (Oriya) Tatar Turkmen Uyghur (Sadly, many of the speakers of Uyghur won’t have access to this tool) Notes Google: These …

Not a huge surprise given the lack of investment over the years and the rise of more full-featured competitors, but Google is shutting down its Translator Toolkit: Google Translator Toolkit …