Unicode is one of the most significant achievements in computing over the past decade. It’s just a shame that so few people know about it.
What the heck is Unicode? Unicode is a universal character encoding. In other words, it’s a really, really big collection of characters. Imagine a typewriter with 90,000 keys. The people behind Unicode set out to merge the character sets of all the world’s major languages into one “super” character set. And, for the most part, they’ve succeeded.
Now for the tough part — getting all those computers and computer users to start using it. This is no trivial task. While Microsoft 2000 and XP are Unicode-based, countless older operating systems and applications are not. If you ever try to input Japanese text into Macromedia Dreamweaver, you’ll know what I mean.
But we’re getting there. The techs at the IETF are inching closer to creating a domain name system that relies on Unicode (and not ASCII). And software makers are also getting there, application by application.
Why do we need Unicode? For starters, if you ever want to create a document or Web page that includes languages that require different character sets (like English and Chinese, French and Arabic, Russian and Tagalog), ASCII will quickly let you down. Unicode won’t.
Here is Unicode in action. Notice how the pull-down menu includes multiple character sets:
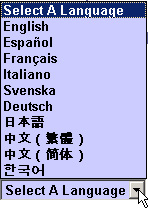
Now here is a more familiar pull-down menu. For a Chinese-speaking user, Chinese characters are going to be much more effective than Roman characters. Unicode will help.
Today I read that the home page of the World Wide Web Consortium went fully Unicode. We are getting there, one Web site at a time…